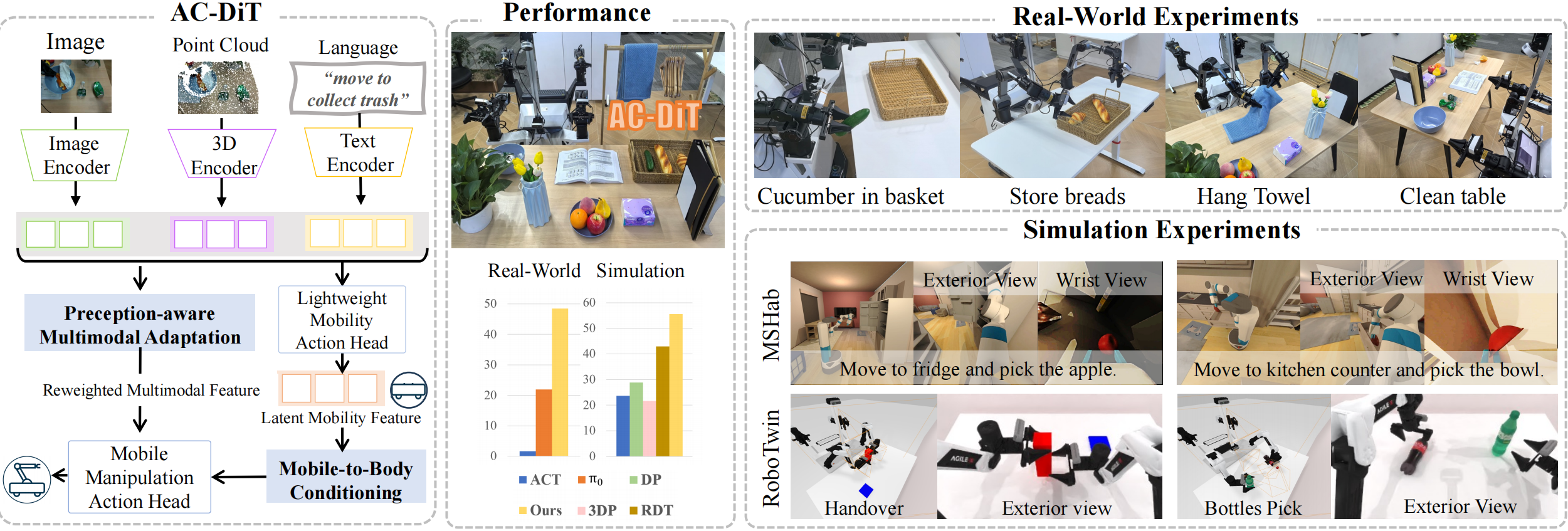
Recently, mobile manipulation has attracted increasing attention
for enabling language-conditioned robotic control in household tasks.
However, existing methods still face challenges in coordinating
mobile base and manipulator, primarily due to two limitations.
On the one hand, they fail to explicitly model the influence of
the mobile base on manipulator control, which easily leads to
error accumulation under high degrees of freedom.
On the other hand, they treat the entire mobile manipulation
process with the same visual observation modality
(e.g., either all 2D or all 3D), overlooking the distinct
multimodal perception requirements at different stages during
mobile manipulation.
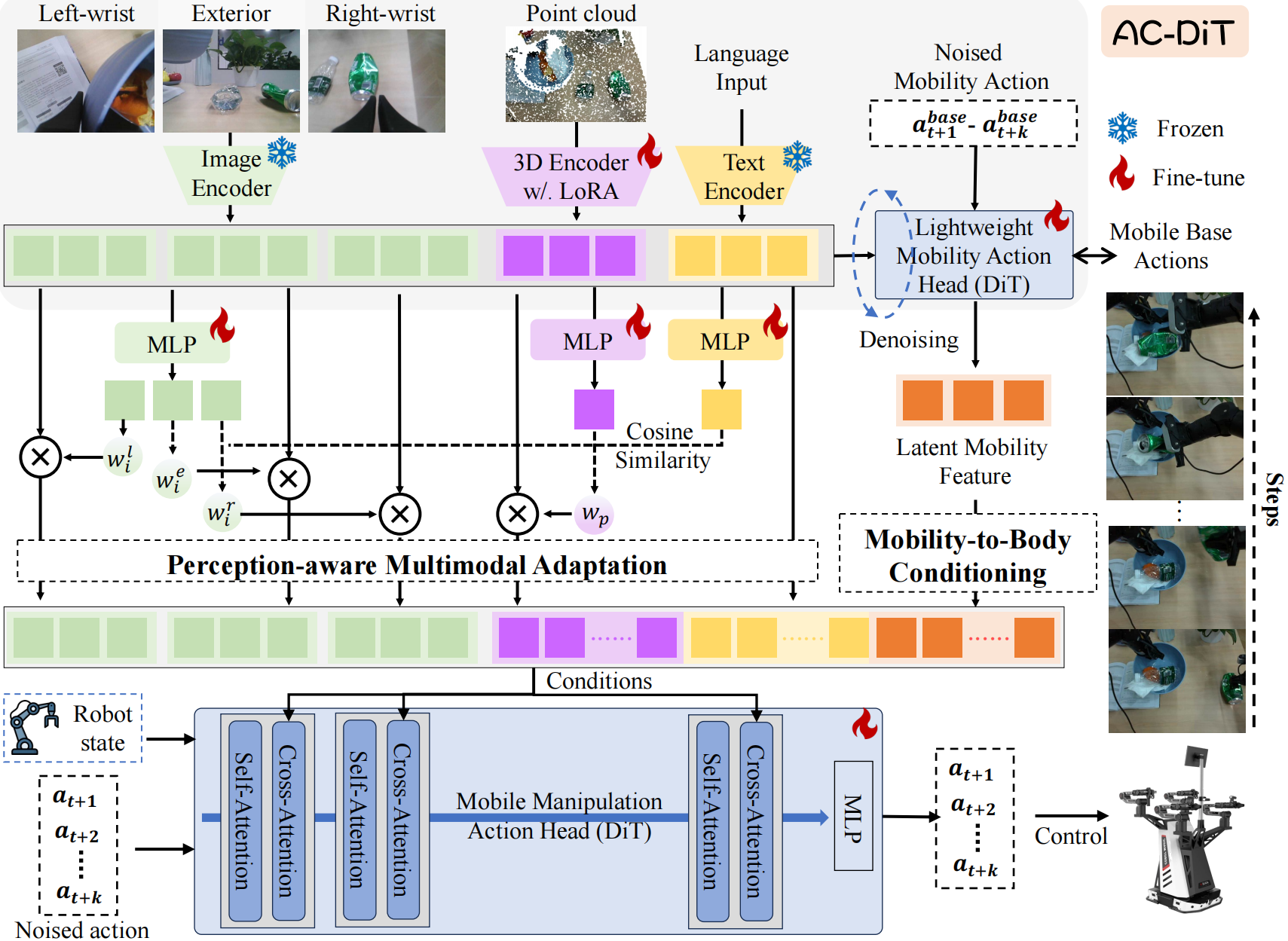
To address this, we propose
the Adaptive Coordination Diffusion Transformer (AC-DiT),
which enhances mobile base and
manipulator coordination for end-to-end mobile manipulation.
First, since the motion of the mobile base directly influences
the manipulator's actions, we introduce a
mobility-to-body conditioning mechanism
that guides the model to first extract
base motion representations, which are then used as context prior
for predicting whole-body actions.
This enables whole-body control that accounts for the
potential impact of the mobile base's motion.
Second, to meet the perception requirements at different stages of
mobile manipulation, we design a
perception-aware multimodal conditioning strategy
that dynamically adjusts the fusion weights
between various 2D visual images and 3D point clouds,
yielding visual features tailored to the current perceptual needs.
This allows the model to, for example, adaptively rely more on
2D inputs when semantic information is crucial for action prediction,
while placing greater emphasis on 3D geometric information
when precise spatial understanding is required.
We empirically validate AC-DiT through extensive experiments on
both simulated and real-world mobile manipulation tasks,
demonstrating superior performance compared to existing methods.